
Desde meados de setembro, o mundo começou a ver a escalada nos preços das memórias RAM por causa da altíssima demanda de data centers de IA. Agora, o mesmo causador dessa situação parece estar ajudando a amenizar a situação. Um novo algoritmo anunciado pelo Google na semana passada já começou a derrubar os preços em algumas lojas.
-
6 dicas para fugir dos preços altos das memórias RAM
- Crise das memórias em 2026: como escapar do preço inflado e montar um PC
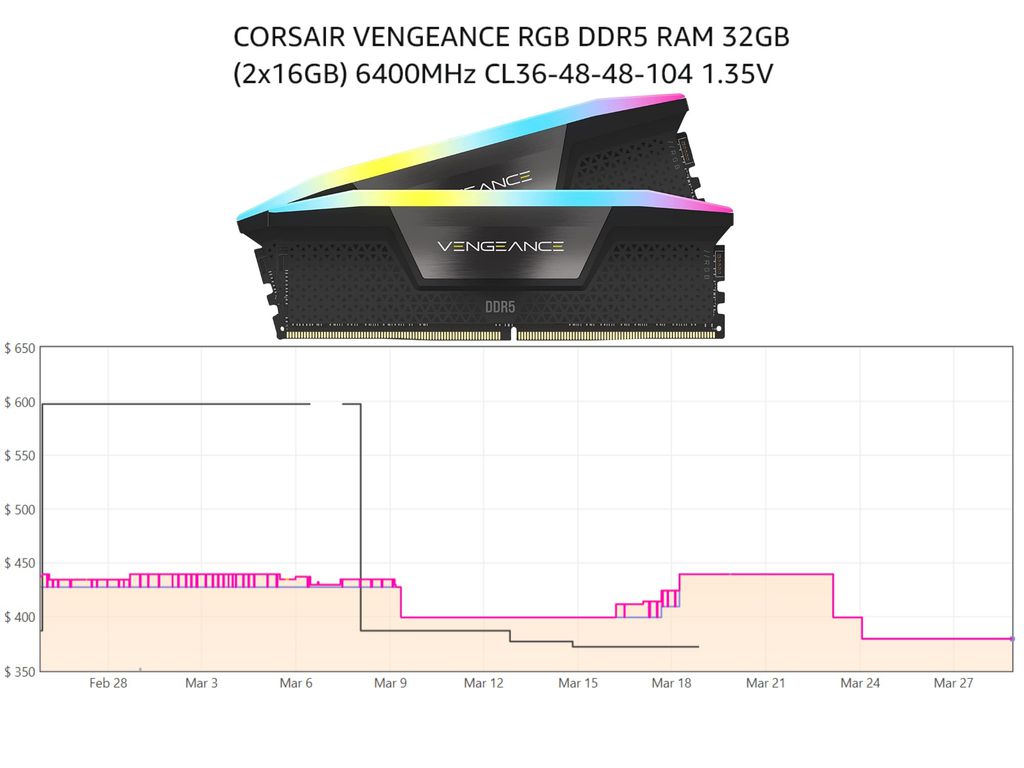
Na Amazon americana, por exemplo, módulos Corsair Vengeance DDR5 caíram de US$ 439,99 para menos de US$ 379,99 desde o anúncio do TurboQuant pelo Google na última quarta-feira (25). Por enquanto, infelizmente, a queda nos preços ainda não virou uma tendência e não é fácil encontrar módulos de outras fabricantes mais baratos.
Porém ainda em fevereiro, as memórias DDR5 ficaram mais baratas em diferentes territórios. Na Alemanha, módulos que custavam mais de cerca de € 480 baixaram para menos de € 450, chegando em alguns casos a € 429. O motivo nesse caso? Difícil saber por enquanto.
-
Entre no Canal do WhatsApp do Canaltech e fique por dentro das últimas notícias sobre tecnologia, lançamentos, dicas e tutoriais incríveis.
-
O que é o TurboQuant e como ele afeta as memórias
Para entender como um algoritmo do Google pode baixar o preço das memórias, primeiro é preciso entender o que está causando o "caos" do mercado. O grande vilão (ou herói, dependendo para quem você pergunta) são os LLMs (Large Language Models), como o ChatGPT e o Gemini.
Essas IAs possuem uma memória de curto prazo chamada KV Cache (Key-Value Cache). Sempre que você conversa com uma IA, ela precisa armazenar todo o contexto da conversa nesse cache para não se perder. O problema? Esse processo consome uma quantidade absurda de memória RAM (e VRAM nas GPUs). Com os data centers rodando milhões de conversas simultâneas, a demanda por chips de memória de alta performance disparou, drenando o estoque global.
É aqui que entra o TurboQuant. A nova tecnologia do Google é um algoritmo de quantização avançado. De forma simplificada, a quantização é o processo de reduzir a precisão dos dados para que eles ocupem menos espaço. Até então, comprimir esses dados de 16-bit ou 8-bit para valores menores resultava em uma perda drástica de "inteligência" da IA. O TurboQuant conseguiu o que parecia impossível: comprimir o KV Cache para apenas 3-bits sem perda perceptível de precisão.
Em se tratando de memória RAM, a lógica é puramente de oferta e demanda. Se um servidor de IA antes precisava de, por exemplo, 1 TB de RAM para atender um determinado número de usuários, com o TurboQuant ele consegue realizar a mesma tarefa ocupando quase um quarto desse espaço. Assim, sobra mais memória para o mercado, mas é preciso esperar mais para vermos o desenrolar dessa história para termos certeza.
Leia a matéria no Canaltech.