A Apple pode até estar atrasada quando o assunto são recursos de inteligência artificial nos seus dispositivos, mas isso não quer dizer que a empresa não esteja fazendo pesquisas nessa área. Na última semana, por exemplo, a companhia publicou um estudo que descreve um modelo de IA capaz de gerar objetos 3D a partir de uma única imagem.
Intitulado “LiTo: Surface Light Field Tokenization”, ele se destaca ao propor uma abordagem que permite reconstruir o modelo tridimensional em questão de acordo com a forma como a luz interage com ele de diferentes ângulos. Como explicado pela Maçã, modelos comuns tendem a seguir dois caminhos: “reconstruir a geometria 3D ou prever a aparência difusa independente do ponto de vista”, o que torna resultados realistas mais difíceis de serem obtidos quando há mais de uma perspectiva.
Essa reconstrução, vale notar, acontece em tempo real — coisa que só é possível pois o LiTo armazena as informações sobre o objeto (incluindo a forma como ele interage com a luz) em um espaço latente na forma de representações matemáticas. Como explicado pelo 9to5Mac, isso livra os pesquisadores de terem que salvar cada detalhe visível do objeto individualmente, o que também poupa poder de processamento e torna tudo mais rápido.
Nossa abordagem aproveita o fato de que imagens RGB-depth fornecem amostras de um campo de luz superficial. Ao codificar subamostras aleatórias desse campo de luz superficial em um conjunto compacto de vetores latentes, nosso modelo aprende a representar tanto a geometria quanto a aparência dentro de um espaço latente 3D unificado. Essa representação reproduz efeitos dependentes do ponto de vista, como reflexos especulares e reflexos de Fresnel sob iluminação complexa.
Ainda de acordo com as informações, o modelo lança mão de um decodificador para fazer o caminho inverso e transformar essas informações em uma geometria completa e representar efeitos de luz como reflexos, realces e mais de diferentes pontos de vista.
O treinamento
Os pesquisadores da Maçã utilizaram milhares de objetos 3D renderizados de diversos ângulos para treinar o LiTo. No entanto, em vez de inseri-los diretamente no modelo, eles optaram por pegar amostras aleatórias e comprimi-las em uma representação latente.
Essa representação latente foi então recebida pelo decodificador, que foi treinado para interpretar representações latentes que capturam tanto a geometria do objeto quanto a forma como sua aparência muda dependendo do ângulo de visão.
Por fim, eles treinaram outro modelo, que recebe uma única imagem de um objeto e prevê a representação latente correspondente, delegando ao decodificador a tarefa de reconstruir e adicionar o restante dos detalhes e os efeitos de luz.
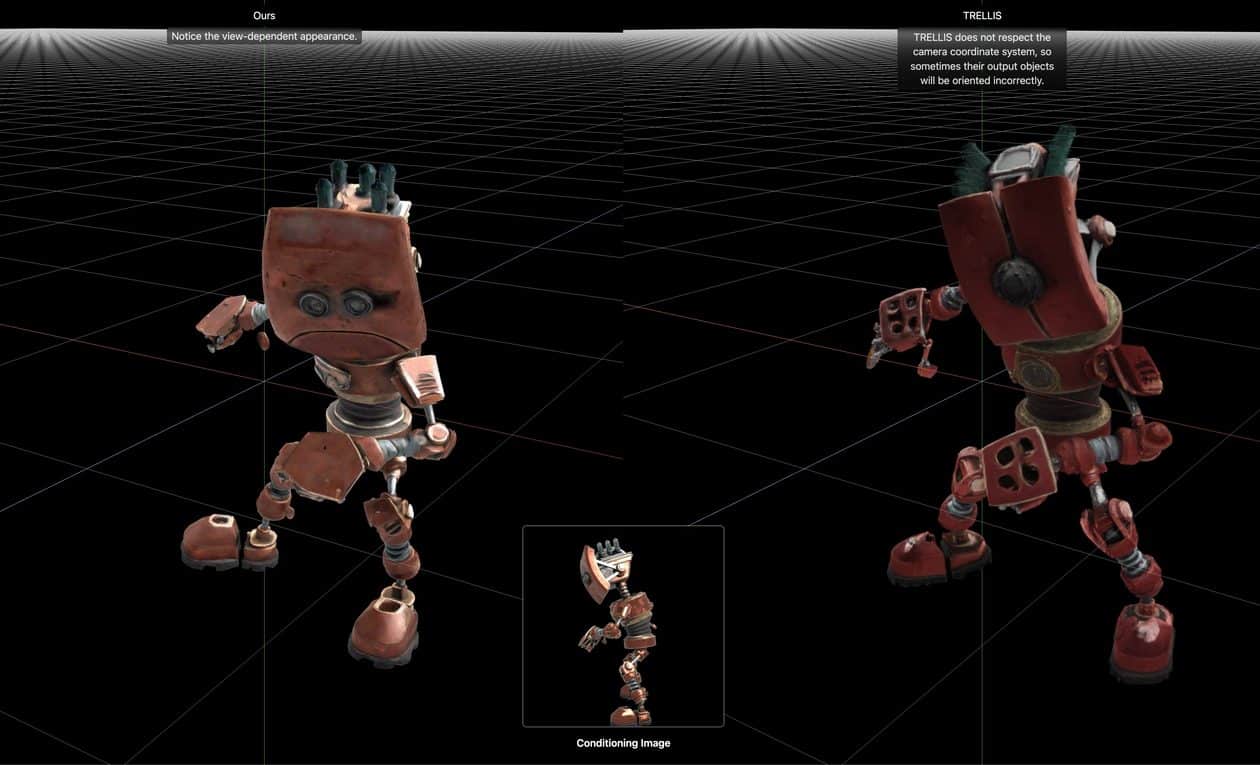
Para melhor ilustrar o seu modelo, a Apple colocou no ar uma página no GitHub com comparações interativas entre o LiTo e outros métodos, como o TRELLIS.
O estudo completo, por sua vez, pode ser conferido aqui.